New paper: Remarks on multimodality
I’m really excited to announce that my 2022 is kicking off with a new paper! This one is written with my colleague Joost Schilperoord, Remarks on multimodality: Grammatical interactions in the Parallel Architecture and appears in Frontiers in Artificial Intelligence.
When we communicate, we typically don’t use just one modality. Though speech is often given priority, most of our expressions combine speech with gesture and text with pictures (among other more complex combinations).
This paper presents a model of the architecture of language that incorporates the vocal, bodily, and graphic modalities all into one system. The idea is that multimodality doesn’t bring together separate systems into something bigger, but that there is one system, and expressions of single modalities and multimodality are emergent states from within that single architecture.
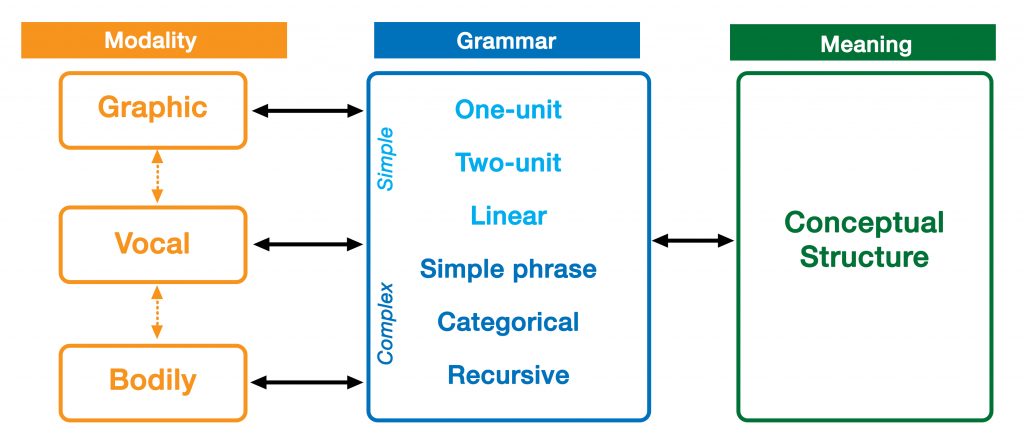
This paper revises a previous iteration of my efforts to articulate a multimodal parallel architecture (pdf). The changes grew out of my teaching a class on multimodality with Joost for several years at Tilburg University, and we are now better able to account for the range of multimodal phenomena that occur in communication.
The emphasis for this paper is on how grammars in different expressions combine with each other. We argue for two dimensions of grammatical interactions: symmetry and allocation. We show that various expressions use similar grammatical interactions, even in different modalities, and that these interactions also persist in single modalities, like in code switching between two spoken languages.
We plan to address other specific aspects of interactions in our architecture in future papers, such as the interactions between modalities, and the interactions between meanings. We are also writing all of this into a larger book.
Much of the paper is also described in my recent Abralin talk in this video. I go through the model and its grammatical interactions, and then talk about how a model like this warrants a reconsideration of what language is and how we study it.
Abstract:
Language is typically embedded in multimodal communication, yet models of linguistic competence do not often incorporate this complexity. Meanwhile, speech, gesture, and/or pictures are each considered as indivisible components of multimodal messages. Here, we argue that multimodality should not be characterized by whole interacting behaviors, but by interactions of similar substructures which permeate across expressive behaviors. These structures comprise a unified architecture and align within Jackendoff’s Parallel Architecture: a modality, meaning, and grammar. Because this tripartite architecture persists across modalities, interactions can manifest within each of these substructures. Interactions between modalities alone create correspondences in time (ex. speech with gesture) or space (ex. writing with pictures) of the sensory signals, while multimodal meaning-making balances how modalities carry “semantic weight” for the gist of the whole expression. Here we focus primarily on interactions between grammars, which contrast across two variables: symmetry, related to the complexity of the grammars, and allocation, related to the relative independence of interacting grammars. While independent allocations keep grammars separate, substitutive allocation inserts expressions from one grammar into those of another. We show that substitution operates in interactions between all three natural modalities (vocal, bodily, graphic), and also in unimodal contexts within and between languages, as in codeswitching. Altogether, we argue that unimodal and multimodal expressions arise as emergent interactive states from a unified cognitive architecture, heralding a reconsideration of the “language faculty” itself.
Comments