



Visual Language Research
Visual languages are the systems we use when we create graphics, just like spoken languages are the systems we use when we speak. Similarly, research on visual language covers a wide range of topics, just like the study of spoken and signed languages. You can find all of our research on the Downloadable Papers page.
We study all aspects of visual language, from the structure of individual drawings, emoji, or cartoons, to how we make meaning out of sequences of images like in comics. We also explore how graphics and writing combine, along with how we learn to do all these things.
Since visual language is a natural part of human cognition alongside spoken or signed languages, we can study it using various methods of the cognitive and language sciences. Broadly, these methods include…
Theory
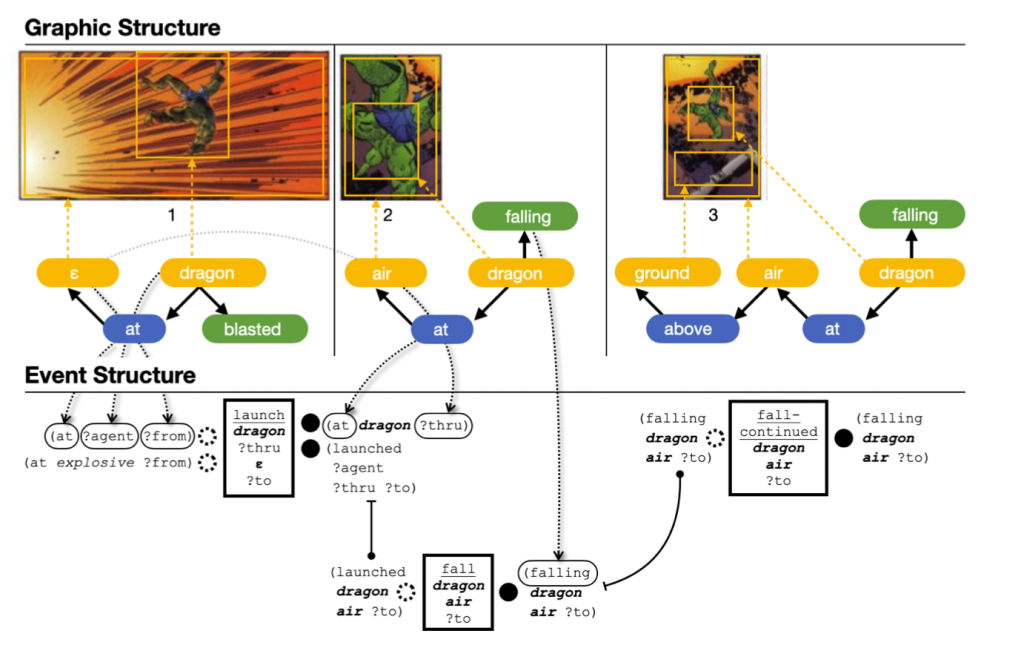
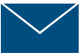
What is the structure of individual images and sequential images? That is, what knowledge do we hold in our minds that allows us to make sense of pictures and/or language? The central argument of Visual Language Theory is that graphic communication is organized using the same structures and principles as language, and thus we draw on methods from linguistics research to construct theoretical models. Specifically, we argue that our capacities to speak, gesture, and drawn are all integrated into a single architecture of communication in the human mind.
These theories provide the foundation for…
Cognition and neuroscience
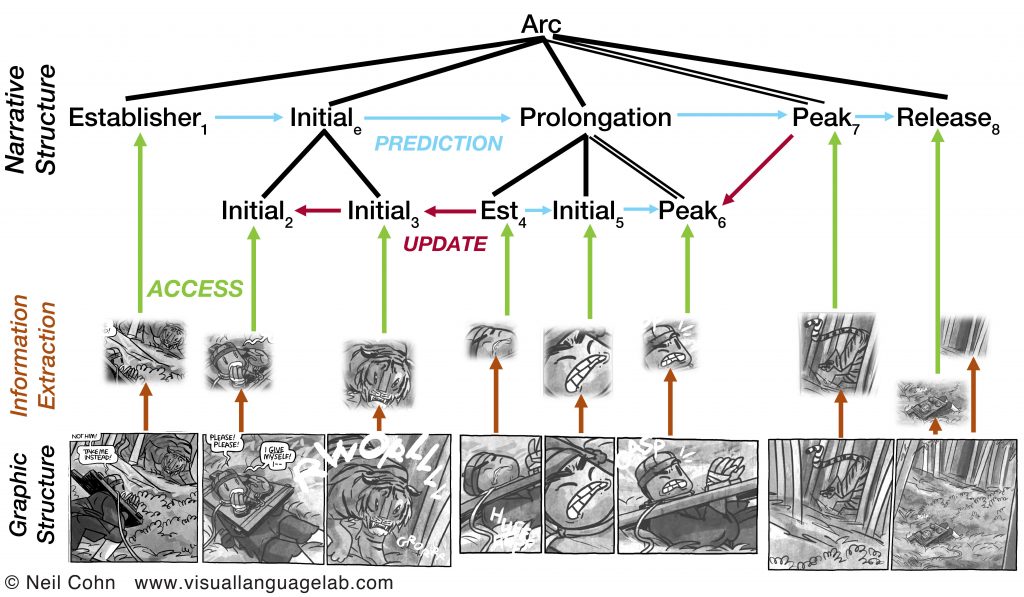
How do our brains make meaning out of pictures and sequential images, like in comics? We use a range of techniques from experimental psychology to explore the cognition of visual language. These include behavioral techniques, like measuring how long people spend viewing pictures or reading comics, how comprehensible they find them, or where their eyes move when viewing them. We also measure people’s brain directly using EEG, resulting in brainwaves. This analysis has shown that the same brainwaves appear to sequential images as we see to sentences.
Our cognitive analysis also asks about how people might differ in their ability to understand sequential images. As described in my book, Who Understands Comics?, understanding visual narratives requires a fluency gained through exposure and experience. We also study how neurodiversities affect the comprehension of visual narratives, particularly autism.
Corpus linguistics
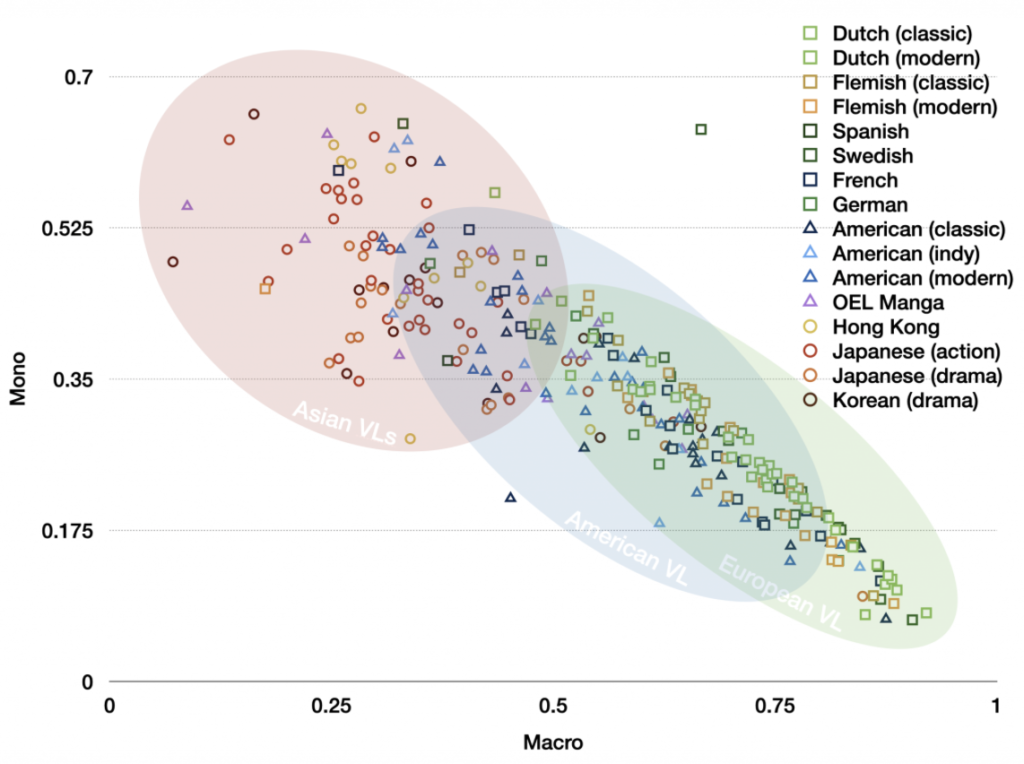
Though drawings are often assumed to be universal, visual languages in fact differ around the world, just like spoken and signed languages. For example, the stereotypical “styles” of American superhero comics and Japanese manga differ from each other, since they constitute different visual languages. We have worked to study this cross-cultural diversity by annotating the properties of comics from around the world, and using corpus linguistics methods to investigate their patterns. We began this by building our Visual Language Research Corpus (VLRC) to compare 300+ comics from Asia, Europe, and North America. In our TINTIN Project, we have created the Multimodal Software Analysis Tool (MAST) to carry out annotations digitally, along with extensive analysis of comics from over 60 countries around the world. Both our software and all our annotation data will be made open.
Computation
With the rise of computers, computational tools have become a central way in which scholars study language and the mind. In our research, we’ve been applying methods from computational linguistics to analyze the structures in visual narrative sequencing, particularly in our collaboration with Aditya Upadhyayula. In addition, along with Chris Martens and Rogelio E. Cardona-Rivera we’ve been examining how to program a computer to generate a visual narrative. Also, in consulting work for BBC News Labs, I helped provide a theoretical framework for them to design a program to automatically generate news comics. Finally, we have begun collaborating with the Sequential Art Image Laboratory who have been studying computer vision and comics for over 10 years.