



VLRC Project
Visual Language Research Corpus
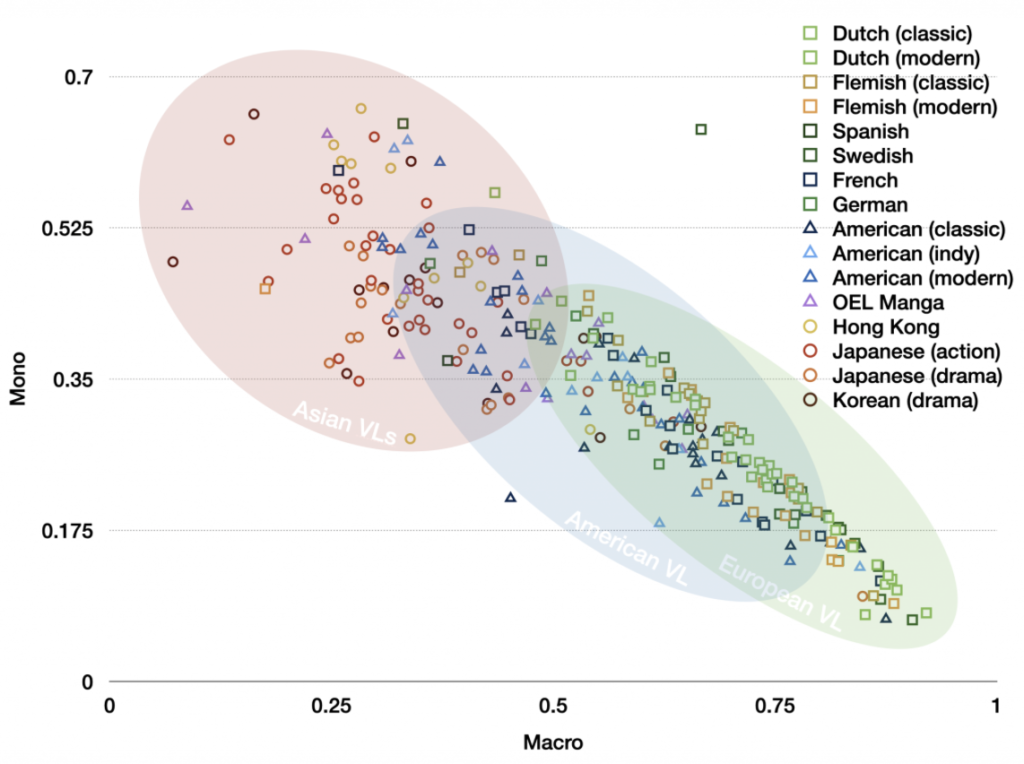
How do the visual languages used in comics around the world differ? Are their structures all universally the same? Do they differ? To start answering these questions, we built the Visual Language Research Corpus (VLRC), a corpus of ~38,000 annotated panels from 360+ comics from Europe, Asia, and the United States, across time periods (1940-present), and various genres. It also includes annotation of the entire run of the Calvin & Hobbes comic strip.
The VLRC includes coding of panel framing, semantic relations between panels, external compositional structure (page layout), multimodality, and a variety of other structures of visual languages.

An extensive analysis of the VLRC data is described throughout Neil Cohn’ book, The Patterns of Comics.
We are continuing corpus research with the TINTIN Project funded by a European Research Council Starting Grant.
Want to read more about the VLRC Project? Check out our VLRC related blog posts with periodic updates and insights.
Repository for VLRC Data: DataverseNL
Publications using the VLRC
These publications also report patterns found in the VLRC:
- Cohn, Neil, Bruno Cardoso, Bien Klomberg, and Irmak Hacımusaoğlu. 2023. The Visual Language Research Corpus (VLRC): An annotated corpus of comics from Asia, Europe, and the United States. Language Resources and Evaluation. (Read online)
- Hacımusaoğlu, Irmak, Bien Klomberg, and Neil Cohn. 2023. Navigating Meaning in the Spatial Layouts of Comics: A cross-cultural corpus analysis. Visual Cognition. (Read online)
- Cohn, Neil, Irmak Hacımusaoğlu, and Bien Klomberg. 2023. The framing of subjectivity: Point-of-view in a cross-cultural analysis of comics. Journal of Graphic Novels and Comics. 14 (3):336-350 (Read online)
- Hacımusaoğlu, Irmak and Neil Cohn. 2022. Linguistic Typology of Motion Events in Visual Narratives. Cognitive Semiotics. 1-26. (Read online)
- Klomberg, Bien, Irmak Hacımusaoğlu, and Neil Cohn. 2022. Running through the Who, Where, and When: A cross-cultural analysis of situational changes in comics. Discourse Processes. (Read online)
- Cohn, Neil. 2020. Who Understands Comics?: Questioning the Universality of Visual Language Comprehension. London: Bloomsbury.
- Cohn, Neil. 2019. Structural complexity in visual narratives: Theory, brains, and cross-cultural diversity. In Grishakova, Marina and Maria Poulaki (Ed.). Narrative Complexity and Media: Experiential and Cognitive Interfaces. (pp. 174-199). Lincoln: University of Nebraska Press. (PDF)
- Cohn, Neil, Jessika Axnér, Michaela Diercks, Rebecca Yeh, and Kaitlin Pederson. 2019. The cultural pages of comics: Cross-cultural variation in page layouts. Journal of Graphic Novels and Comics. 10(1): 67-86 (PDF)
- Cohn, Neil, Ryan Taylor, and Kaitlin Pederson. 2017. A picture is worth more words over time: Multimodality and narrative structure across eight decades of American superhero comics. Multimodal Communication. 6(1): 19-37. (PDF, Video Presentation)
- Cohn, Neil, Vivian Wong, Kaitlin Pederson & Ryan Taylor. 2017. Path salience in motion events from verbal and visual languages. In G. Gunzelmann, A. Howes, T. Tenbrink, & E. J. Davelaar (Eds.), Proceedings of the 39th Annual Conference of the Cognitive Science Society (pp. 1794-1799). Austin, TX: Cognitive Science Society. (PDF, Poster PDF)
- Pederson, Kaitlin and Neil Cohn. 2016. The changing pages of comics: Page layouts across eight decades of American superhero comics. Studies in Comics. 7(1): 7-28. (PDF, Video Presentation)
Contributors
Several publishers have contributed to this research by generously donating comics to our corpus of research materials. They include:
- Antarctic Press
- Archie Comics
- Dark Horse Comics
- Drawn & Quarterly
- Fantagraphics Books
- First Second Books
- Humanoids Inc
- IDW Publishing
- NBM Publishing
- NetComics
- Oni Press
- Top Cow
- Top Shelf
- Udon Entertainment
- Vertical Inc
- Viz Media
Their support is greatly appreciated! If you or your company would like to donate materials to our current research, please contact me.
Contributors
The VLRC was coded by several student researchers at UC San Diego and Tilburg University. They include:
Jessika Axnér, Justin Brookshier, Michaela Diercks, Mark Dierick, Sean Ehly, Ryan Huffman, Kaitlin Pederson, Ryan Taylor, Lincy van Middelaar, Vivian Wong, Rebecca Yeh