



Resources
Resources
We have now been carrying out visual language research for over 20 years. Through this experience, we’ve developed several techniques, tools, and other resources that can benefit researchers and educators. Below we describe several of these resources along with links to find more.
Visual Language Research and Teaching
My theory of Visual Narrative Grammar (VNG) seeks to explain how people comprehend sequential images. However, the complexity of this theory makes it somewhat challenging when students or researchers may wish to use it. This tutorial provides a step-by-step guide for the basic procedures and diagnostics that should be used when analyzing sequential images.
- How to analyze visual narratives: A tutorial in Visual Narrative Grammar (PDF)
Within VNG we’ve characterized lots of patterns used by visual narratives. Among these are various techniques used to signal unseen information and motivate inferences. A concise listing of these is in the image shown here, and some people find it useful for sharing in classrooms or teaching. For a high-res version of the 12 techniques in the figure to the right, for use in classrooms, click here (10MB).

Visual Language Fluency
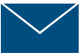
Many people assume that the sequential images found in comics and picture stories are universal to comprehend. However, our research has found that in fact sequences of images require a fluency to understand, just like any other language. In our research, we’ve developed measures to be able to adequately assess this fluency.
So, if you are doing studies on comics or using them in education, we encourage you to check out and download our resources about Visual Language Fluency.
Multimodal Annotation Software Tool (MAST)
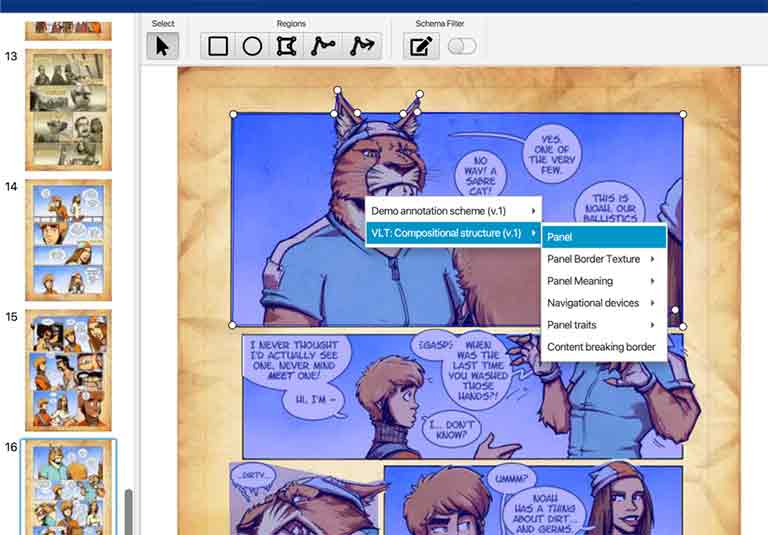
As part of our TINTIN Project, we’ve been developing software for better enabling the annotation of visual and multimodal material. Designed by our postdoctoral researcher Bruno Cardoso, this Multimodal Annotation Software Tool (MAST) allows a user to select a visual area of a document, and then annotate with any classifications that a user has specified. MAST also allows for multiple users to annotate the same document, and to establish relationships between annotations, such as to build dependencies or hierarchic structures.
We intend MAST to be available openly for other researchers, so watch this space for announcements and links.
Visual Language Corpora
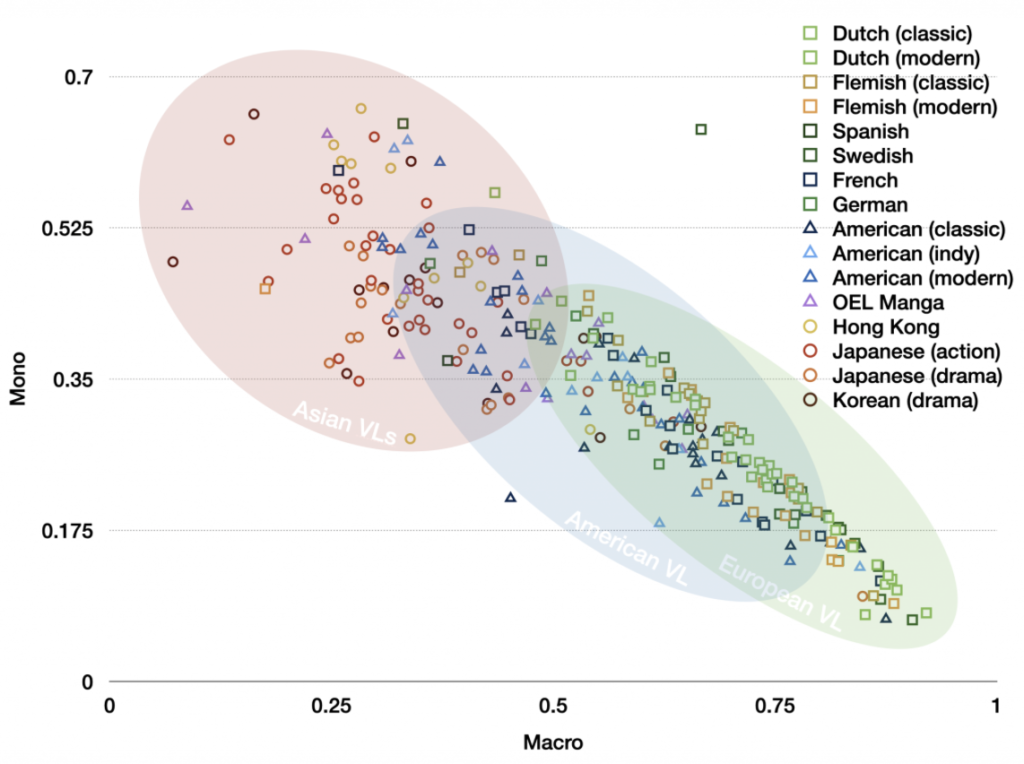
One of our primary questions is about how visual languages differ across cultures, especially those used in comics. To study this, we’ve analyzed the properties of comics around the world and then have analyzed this data to discover patterns and trends of different systems. All of our data will be made available here for other researchers to analyze too, so watch this space for when our data is released. There are two primary projects:
The Visual Language Research Corpus (VLRC) – An analysis of 300+ comics from Europe, Asia, and the United States across various dimensions of structure.
The TINTIN Project – An ongoing project intending to annotation the properties of 1,500 comics from 60+ countries, using our Multimodal Annotation Software Tool (MAST).