2016: My Publications in Review

As 2016 nears its close, I thought I should do a post reflecting on all the research I’ve released with my colleagues over the past year. This was my biggest year of publishing yet, so I thought it would be good to just go over what we came out with.
First off, in January, Bloomsbury published my edited volume The Visual Narrative Reader. The book features 12 chapters summarizing or reprinting important and often overlooked papers in the field of visual narrative research, with topics ranging from metaphor theory and multimodality, to how kids draw and understand sequential images, to various examinations of cross-cultural and historical visual narrative systems. In my classes, I use it as a companion volume to my monograph, The Visual Language of Comics.
The rest of the year then saw a flurry of publications (title links go to blog summaries, pdf links to pdfs):
A multimodal parallel architecture (pdf) – Outlines a cognitive model for language and multimodal interactions between verbal (spoken language), visual-graphic (drawings, visual languages), and visual-bodily (gesture, sign languages) modalities. This paper essentially presents the core theoretical model of my research, and my vision for the cognitive architecture of the language system.

The vocabulary of manga (pdf) – This project with Sean Ehly coded over 5,000 panels in 10 shonen and 10 shojo manga to reveal that they mostly use the same 70 visual morphemes (“symbology”), though they use them in differing proportions. This suggested that there is a broad Japanese Visual Language in which genre-specific “dialects” manifest variations on this generalized structure.
The pieces fit (pdf) – This experiment with Carl Hagmann tested participants’ comprehension of sequential images with rapidly presented panels (1 second, half a second) when we switched the positions of panels. In general, switches between panels nearby to each other in the original sequence were easier to comprehend than panel switches across distances, but switches that crossed boundaries of groupings (” narrative constituents”) were worse than those within groupings. This provides further evidence that people make groupings of panels, not just linear panel transitions.
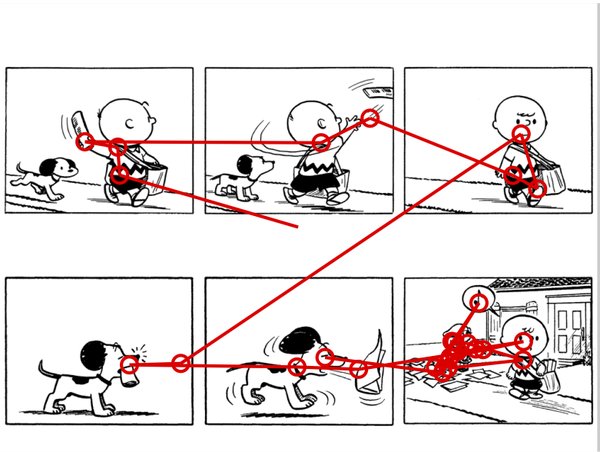
Reading without words (pdf) – My project with collaborator Tom Foulsham reports on one of the first controlled eye-tracking studies using comics. We show that people’s eyes move through a grid layout largely the same as they would across text—left-to-right and down largely keeping to their row, and looking back mostly to adjacent frames. We also found that people mostly look at the same content of a panel whether shown in a grid or with one panel at a time, but eye fixations to panels from scrambled sequences are slightly more disperse than those to panels in normal sequences.
Meaning above the head (pdf) – This paper with my student Beena Murthy and collaborator Tom Foulsham explored the understanding of “upfixes”—the visual elements that float above characters’ heads like lightbulbs or hearts. We show that upfixes are governed by constraints that the upfix needs to go above the head, not next to it, and must “agree” with the facial expression (storm clouds can’t go above a happy face). These constraints operate over both conventional and novel upfixes, suggesting that this is an abstract schematic pattern.
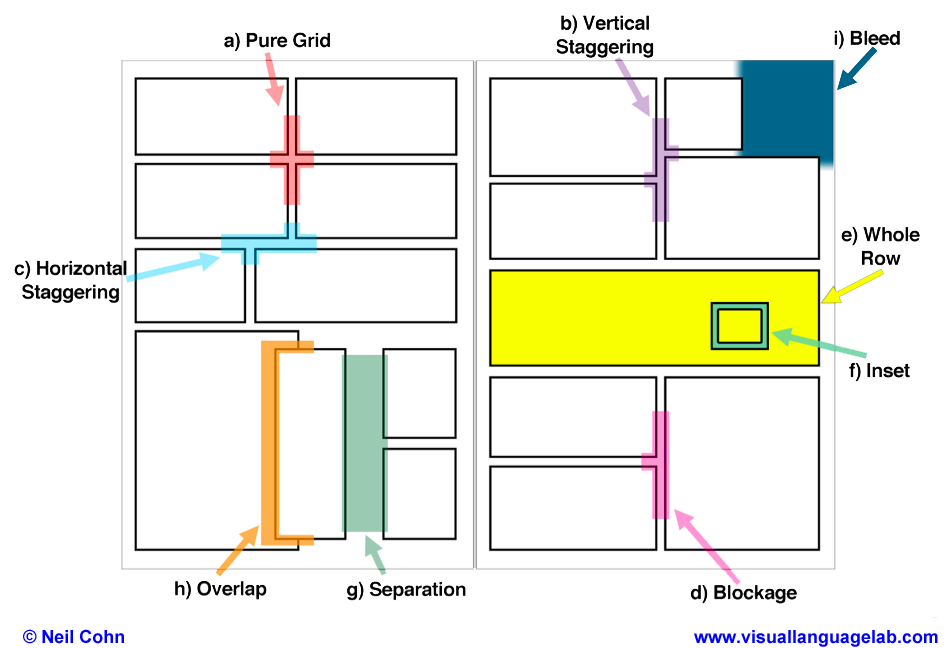
The changing pages of comics (pdf) – My student Kaitlin Pederson and I report on her project coding over 9,000 panels in 40 American superhero comics from the 1940s through the 2010s to see how page layout has changed over time. Overall, we argue that layouts over time have become both more systematic as well as more decorative.
Pow, punch, pika, and chu (pdf) – Along with students Nimish Pratha and Natalie Avunjian, we report on their analyses of sound effects in American comics (Mainstream vs. Indy) and Japanese manga (shonen vs. shojo) and show that the structure and content of sound effects differ both within and between cultures.
Sequential images are not universal, or caveats for using visual narratives in experimental tasks (pdf) – This conference proceedings paper reviews some of the research showing that sequential images are not understood universally, and are dependent on cultural and developmental knowledge to be understood.
Finally, I also had a book chapter come out in the book Film Text Analysis by Janina Wildfeuer and John Bateman. My chapter, “From Visual Narrative Grammar to Filmic Narrative Grammar” explores how my theory of narrative structure for static sequential images can also be applied to explaining the comprehension of film. I’ll hopefully do a write up of it on this site sometime soon.
It was a big year of publications, and next year will hopefully be just as exciting! All my papers are available on this page.
Comments