Corpus analyses of comics
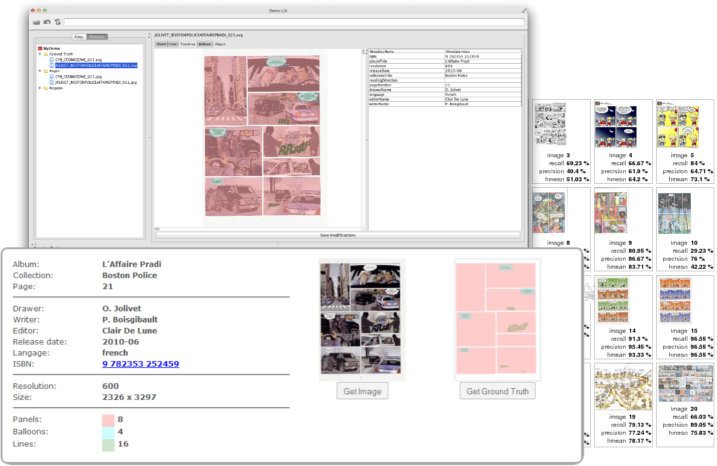
I stumbled across this interesting project called the eBDtheque database which has started coding various comic pages to create a searchable corpus. The full project is online here, while their paper describing the project is found in this pdf.
This rather large research group looks like it’s actually been doing quite a lot of computational approaches to analyzing comics, which is very cool.
Besides recording background information about the authors, publishers, etc. of the comics, this database in particular seems to take comic pages and code them across three main dimensions. 1) How many panels per page, 2) how many balloons per page, 3) how many lines of text within balloons.
While this coding scheme is fairly limited, they have said that they’ll be expanding it to look at other dimensions, such as the angle-of-viewpoint and filmic shot type. What makes the project fairly impressive though, is that the data in this corpus is not just human coded, but also involves extraction from the computers themselves. All that makes this a project worth watching.
Naturally, I’d love to see this type of project be developed further. My two cross-cultural studies so far comparing panels coded from Japanese and American comics are hints of what having a corpus will allow. I have a research library so far of roughly 4,000 comics and graphic novels that is ripe for research to be done on them. The compelling idea here though is not just doing isolated studies. Rather, the idea would be to create a massive database that could be searched in many different ways for various inquiries across many dimensions. In fact, I had talked with programming savvy friends about starting such a project years ago.
Once my own actual lab is up and running, I’d like to start on a project like this by recruiting students to help with the coding. However, another way to build a large database is to “crowdsource” the work. This would involve having people across the world complete “training” sessions to become proficient at the theories and coding schemes involved, and then they could login and code comics they have around them.
This would help with creating a large, internationally diverse corpus available to many scholars to use, and would be created by people across the world. Imagine being able to do large scale searches across millions of comic panels from across the world in order to do comparisons about the structure of visual language!
Comments